





Els benchmarks d’agents d'IA no compleixen els requisits del sector públic
Les organitzacions del sector públic volen beneficiar-se de les capacitats de sistemes d’IA cada vegada més potents i autònoms. Per fer-ho, necessiten mesures fiables i específiques del context sobre les capacitats, els riscos i les limitacions d’aquests sistemes. El nostre treball mostra que els benchmarks actuals d’IA no estan a l’altura d’aquest repte.

Atesa la seva ràpida adopció, la utilitat dels sistemes d’intel·ligència artificial (IA) basats en models de llenguatge a gran escala (LLM) per a les operacions de les organitzacions del sector públic (OSP) és innegable. En algunes jurisdiccions, ja s’utilitzen de manera generalitzada per a tasques com la resumització i la generació de textos, la navegació per bases de coneixement o fins i tot el suport als processos de presa de decisions, sovint sense iniciatives centralitzades que n’impulsin l’adopció (Bright, 2024).
Recentment, l’atenció de la indústria s’ha orientat cap als agents basats en LLM: sistemes que no es limiten a produir sortides quan són interpel·lats per humans, sinó que poden “actuar” de manera autònoma mitjançant la integració directa amb altres programes informàtics, perseguir tasques abstractes i complexes mitjançant passos seqüencials i ampliar el seu propi comportament amb memòria. (Quina combinació exacta d’aquests elements fa que un sistema sigui considerat un “agent” continua sent objecte de debat; cf. Kasirzadeh i Gabriel, 2025). En teoria, els sistemes agentius s’adapten molt bé al govern: funcionen millor en contextos amb dades riques, procediments documentats i precedents, condicions que la majoria de OSP compleixen àmpliament.
Tanmateix, tal com és ben conegut en el camp de l’administració pública, l’adopció de sistemes d’IA també comporta tota mena de riscos per a les OSP i els valors que representen, com ara la legitimitat dels processos, la transparència i la neutralitat. Els sistemes agentius generen versions més immediates d’aquests riscos, ja que poden tenir un impacte molt més directe en les estructures en què s’integren. Tal com discutim en treballs anteriors (Schmitz et al., 2025), la gestió d’aquests riscos a les OSP requereix un règim sòlid de supervisió tècnica que inclogui responsabilitats com l’auditoria, la visibilitat operativa i la coordinació interdepartamental.
En aquest treball sostenim que la distribució de les tasques de supervisió d’agents dins de les OSP desafia les seves estructures tradicionalment jeràrquiques i compartimentades, fins i tot quan està clar en què han de consistir exactament aquestes tasques. No obstant això, un element crucial d’aquesta supervisió —l’avaluació de si un sistema agentiu determinat és adequat per a una tasca— es veu bloquejat molt abans: no és gens clar quin estàndard hauria de complir aquest sistema.
El nostre article avança cap a una resposta a aquesta qüestió intentant fer que la pràctica tècnica del benchmarking en IA sigui més útil per a les OSP. Concretament, desenvolupem de manera iterativa una definició del que constitueix un “bon” benchmark d’agents d’IA per al sector públic, avaluem més de 1.300 benchmarks existents segons aquesta definició i, davant uns resultats preocupants, proposem vies de futur.
Benchmarking en IA: una crisi científica?
L’avaluació sistemàtica dels sistemes d’IA s’anomena benchmarking. Es tracta d’un camp de recerca ampli i molt actiu, amb centenars de benchmarks —conjunts de tasques, preguntes o reptes contra els quals s’avaluen els sistemes d’IA— publicats cada any en congressos d’IA. Els benchmarks tenen un paper important en el desenvolupament de la IA: per exemple, quan es publiquen nous models, habitualment se’n comunica el rendiment en benchmarks clau (potser et resultaran familiars noms com “ARC-AGI”, “SWE-Bench” o “Humanity’s Last Exam”). Les OSP que volen avaluar sistemes agentius poden, per tant, esperar poder recórrer a aquests benchmarks.
Malauradament, el camp del benchmarking es troba en una mena de crisi. S’ha obert una bretxa creixent entre les capacitats que els benchmarks atribueixen als sistemes d’IA (per exemple, resoldre tasques de dues hores) i la seva difusió en el món real. A més, molts benchmarks es “saturen” ràpidament: els nous sistemes d’IA hi obtenen resultats gairebé perfectes, cosa que en redueix el valor diferenciador. Els investigadors han interpretat aquestes dues tendències com un estímul per replantejar si els benchmarks mesuren realment “el que importa”. Un estudi recent homònim (Bean et al., 2025) conclou que els benchmarks de diferents àmbits presenten, en gran mesura, una “validesa de constructe” deficient: són representacions simplificades i esbiaixades d’allò que afirmen mesurar.
Cal reconèixer que articular què hauria de mesurar exactament un benchmark en un àmbit determinat és difícil. El problema recorda la paradoxa borgiana del mapa: així com el mapa perfecte d’un imperi és l’imperi mateix, el benchmark perfecte d’un domini és el domini. El repte central és l’abstracció, és a dir, determinar com cal simplificar les capacitats necessàries per a un domini per tal de poder-les avaluar.
Tal com posa de manifest aquesta literatura, donar una resposta universal a aquesta qüestió és complicat. Nosaltres sostenim que cada àmbit pot, en canvi, recórrer a les seves pròpies abstraccions dels valors i les capacitats que considera rellevants. Convenientment, l’administració pública compta amb més d’un segle de recerca que detalla quins són els valors de les OSP i què fa que els elements d’una organització s’hi ajustin.
Definir un “bon” benchmark d’agents per al sector públic
En el nostre article, “Agent Benchmarks Fail Public Sector Requirements” (Rystrøm et al., 2025), partim d’aquesta tradició de l’administració pública per definir què fa que un benchmark sigui útil per a l’avaluació d’agents per part de les OSP. Identifiquem enfocaments teòrics que han estat àmpliament significatius per a la recerca en el sector públic i n’extreiem quatre elements comuns, que formulem com a criteris per als benchmarks d’agents. El compliment d’aquests criteris no serà suficient per a la majoria de casos d’ús d’agents al sector públic i pot requerir especificacions addicionals, però aspirem a establir un mínim més avaluable.
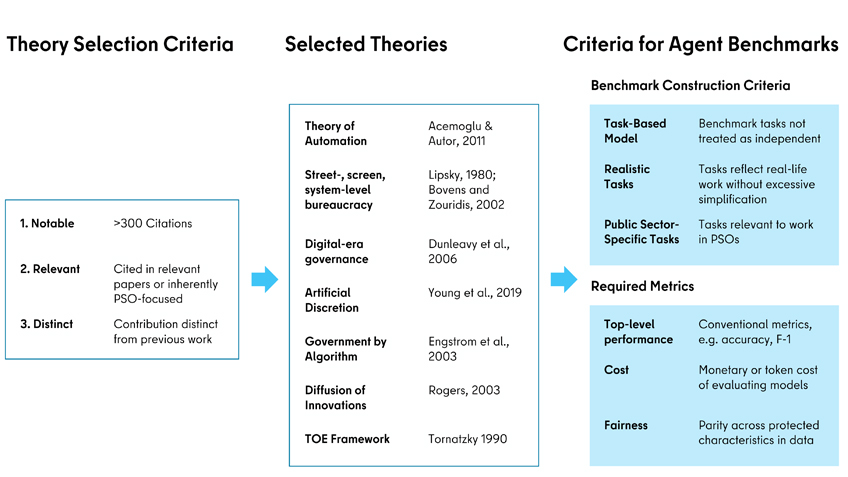
Segons la nostra definició, un benchmark d’agents per al sector públic mínimament “bo” és:
Basat en processos: Moltes teories de l’administració pública comparteixen la descomposició conceptual d’organitzacions, sistemes i llocs de treball en les seves tasques constitutives. Els benchmarks d’agents no haurien de limitar-se a provar aquestes tasques com si fossin independents —com és habitual en els benchmarks de LLM no agentius—, sinó que també haurien de reflectir la seva agregació en superestructures rellevants, especialment en processos. Per exemple, un benchmark sobre la presa de decisions en matèria de prestacions socials hauria de basar-se en un model conceptual de tot el procés, i les tasques avaluades haurien de ser parts d’aquest procés vinculades de manera significativa.
Realista: Les tasques compostes d’un benchmark haurien de correspondre a peces de treball reals que es duen a terme en el context corresponent i no haurien de ser simplificacions excessivament grolleres. Per exemple, les proves de raonament jurídic no haurien d’incloure opcions de resposta múltiple, i si la complexitat d’una tasca del món real rau en l’agregació de dades procedents de múltiples fonts, aquestes dades no haurien de proporcionar-se íntegrament dins del prompt.
Rellevant per al sector públic: Les tasques avaluades haurien de reflectir activitats que realment tenen lloc a l’administració pública, ja sigui capacitats generals presents a la majoria de OSP (com ara el formatatge de dades, la resumització o el reconeixement de caràcters) o tasques específiques desenvolupades per determinades OSP (com l’anàlisi de geodades o la detecció de frau).
Mètriques rellevants: El benchmark no hauria de mesurar únicament el rendiment de nivell superior del sistema, com ara la precisió o la taxa d’èxit, sinó que hauria d’incloure un conjunt més ampli de mètriques. Aquestes haurien d’incorporar el cost i l’equitat. El cost hauria de reflectir fins a quin punt és car o intensiu en temps que un agent realitzi una tasca concreta, mentre que l’equitat hauria d’avaluar —quan sigui pertinent— si l’agent actua de manera neutral i equitativa entre diferents punts de dades.
Hi ha benchmarks “bons” per al sector públic?
A continuació, vam avaluar més de 1.300 benchmarks recents segons els nostres criteris, utilitzant una revisió de la literatura assistida per LLM, amb l’esperança de trobar precedents prometedors en el treball existent. En la pràctica, vam dur a terme diverses rondes de revisió humana sobre un subconjunt d’articles fins a arribar a interpretacions precises i alineades de les definicions anteriors. Posteriorment, vam iterar sobre un prompt del model fins que coincidí amb les valoracions humanes de la mostra, vam generar etiquetes per a la resta d’articles amb aquest prompt i en vam fer comprovacions puntuals. Tot i que l’ús de LLM per a la codificació qualitativa i altres tasques de les ciències socials encara és molt incipient, aquest procés segueix, en la mesura que existeixen, les bones pràctiques emergents.
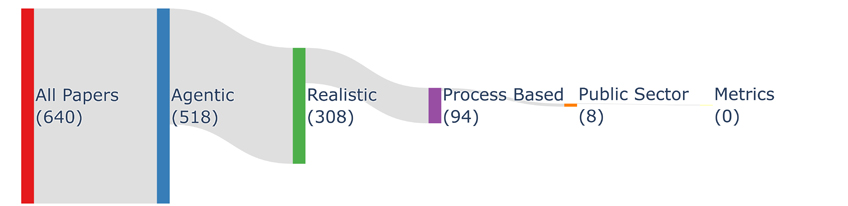
Constatem que cap dels 1.300 benchmarks compleix plenament els nostres requisits. La mancança més habitual és que els benchmarks rarament informen de mètriques més enllà del rendiment de nivell superior, però cap dels quatre criteris es compleix de manera satisfactòria en conjunt. Atès que ni tan sols pretenem establir criteris exigents o exhaustius —sinó simplement un “llindar mínim” perquè els benchmarks siguin significatius per a les OSP—, aquests resultats són preocupants.
I ara què?
Un cop reconegudes les limitacions de les pràctiques actuals de benchmarking, els acadèmics —incloent-nos a nosaltres mateixos— intentaran desenvolupar benchmarks amb una major validesa ecològica per al sector públic. Tanmateix, perquè aquestes avaluacions siguin realment útils a les OSP, caldrà un esforç bidireccional: les avaluacions tècniques d’agents hauran d’anar acompanyades de professionals que sàpiguen interpretar-les i aplicar-les. Amb aquest objectiu, presentem les recomanacions següents.
Recomanacions de política pública
- Prioritzeu, financeu i faciliteu el desenvolupament de benchmarks específics d’IA que reflecteixin les condicions particulars de les institucions del sector públic i les tasques que duen a terme, i/o proporcioneu orientacions sobre l’ús de benchmarks de tercers —per exemple, mitjançant una base de dades de benchmarks adequats associada a estàndards centralitzats de rendiment per a determinats dominis.
- Creeu i manteniu infraestructures tècniques per a l’avaluació de sistemes d’IA dins del sector públic, com ara entorns d’avaluació, programari que registri metadades extenses de les avaluacions d’IA en formats estandarditzats, i faciliteu l’expertesa organitzativa, el finançament i les estructures necessàries.
Recomanacions per als professionals
- A l’hora d’avaluar IA agentiva, considereu amb cura l’adequació de les mètriques i els benchmarks utilitzats per jutjar el rendiment. En particular, eviteu dependre excessivament de les mètriques autodeclarades pels desenvolupadors de models o productes d’IA.
- Sempre que sigui possible, separeu l’avaluació de la IA del desenvolupament o de la contractació en les estructures organitzatives i de projecte: es tracta d’una funció de supervisió, no d’una tasca de gestió de processos o de proveïdors.
- Considereu la combinació de benchmarks i proves per establir un “terra” de rendiment mitjançant una aproximació de tipus formatge suís, utilitzant diferents benchmarks per avaluar capacitats o qualitats diferents.
- Col·laboreu estretament amb acadèmics que treballin per millorar el benchmarking o, idealment, desenvolupeu capacitat interna per dissenyar i mantenir benchmarks.
Chris Schmitz és Research Associate en IA i govern al Centre for Digital Governance, Hertie School – Berlin’s University of Governance. Jonathan Rystrøm és doctorand (DPhil) en Social Data Science a l’Oxford Internet Institute, University of Oxford. Jan Batzner és investigador al Weizenbaum Institute Berlin, el German Internet Institute. Karolina Korgul és doctoranda (DPhil) en Social Data Science i becària Clarendon a l’Oxford Internet Institute, University of Oxford, i imparteix docència en ètica i alineament de la IA a Stanford. Chris Russell és Dieter Schwarz Associate Professor en IA, govern i polítiques públiques a l’Oxford Internet Institute, University of Oxford, i membre fundador del programa Governance of Emerging Technology, un grup de recerca interdisciplinari que analitza els reptes sociotècnics de les noves tecnologies i proposa respostes jurídiques, ètiques i tècniques.
Referències
Bean, Andrew M., Ryan Othniel Kearns, Angelika Romanou, Franziska Sofia Hafner, Harry Mayne, Jan Batzner, Negar Foroutan, et al. 2025. “Measuring What Matters: Construct Validity in Large Language Model Benchmarks.” A The Thirty-Ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=mdA5lVvNcU.
Bright, Jonathan, Florence E. Enock, Saba Esnaashari, John Francis, Youmna Hashem, and Deborah Morgan. 2024. “Generative AI Is Already Widespread in the Public Sector.” doi:10.48550/arXiv.2401.01291.
Kasirzadeh, Atoosa, and Iason Gabriel. 2025. “Characterizing AI Agents for Alignment and Governance.” doi:10.48550/arXiv.2504.21848.
Schmitz, Chris, Jonathan Rystrøm, and Jan Batzner. 2025. “Oversight Structures for Agentic AI in Public-Sector Organizations.” A Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), editat per Ehsan Kamalloo, Nicolas Gontier, Xing Han Lu, Nouha Dziri, Shikhar Murty i Alexandre Lacoste, 298–308. Viena, Àustria: Association for Computational Linguistics. https://aclanthology.org/2025.realm-1.21/.

























És obligatori estar registrat per comentar.
Fes clic aquí per registrar-te i rebre la nostra newsletter.
Fes clic aquí per accedir.